Initializations, views, percentage viewed, (unique) visitors: Just some of the terms and metrics often mentioned in relation to online video analytics. Oh, and preferably we’d like to see them in real time and with as much cross references as you can possibly imagine…
With the growth of online video the need to analyse who saw what and when is growing at a rapid pace. This calls for an agile, endlessly scalable video analytics platform. In this blog post I want to give you a look at the foundations of our very own Big Data platform.
Learn from your mistakes and dare to start over
The main reasons to analyse and completely rebuild our video analytics platform were:
- To improve flexibility: We wanted more metrics, more angles, more everything
- To be able to handle exponential growth in events and number of views
- To shorten the time frame in which analytics information becomes available (speed)
We started with an analysis of our previous “mistakes”. The main architectural anomalies we found are:
- Our previous analytics processing platform depended on a single active storage server. This seriously limited scalability. Even if we would add more “processing power” to the analytics processing application we’d still be held back by the single active database.
- The Analytics processing application itself was monolithic. There was no option to “add extra horsepower” to just some aspects of the processing logic, or use more than one server for processing.
- Rigid data model: Adding metrics, and specifically storing homogenic information was cumbersome to say the least.
These findings led to the following conclusions:
- The processing logic should be split up in several components.
- Each of these components should be suitable for multiple instances.
- The storage backend should be both flexible AND structured
After some ill-fated tries with MongoDB as the storage backend we designed the “final” analytics architecture heavily relying on the “Blue Billywig proven” Apache Solr search engine and the Redis in-memory nosql database engine.
Solr? I thought that was a search engine…
Solr is a Search Engine indeed.. And very good at it. It also has a set of interesting features that make it very suitable for use as an analytics storage platform:
- Facetting, facet ranges and hierarchical facetting (pivot facets)
- Distributed queries
- Dynamic field types
The Blue Billywig video analytics platform relies heavily on these key Solr features:
- Facetting: All filters are “powered by” Solr facets
- Distributed queries: A Solr database (index) is created each month. Solr queries are distributed over all indexes that are relevant for the requested period.
- Dynamic field types: View “documents” are heterogenic documents. Over time fields will be removed or added. Solr allows us to store, retrieve and search through all those fields. It also respects different datatypes for the dynamic fields: e.g. a dynamic date field will actually be indexed as a date and will usable for date range calculation or period filtering.
It goes beyond the scope of this blog post to dive into the full potential of the Solr search engine platform though: Lets’s continue our overview of the Analytics processing architecture.
Harvest and process view data into valuable information
The metaphor we thought of when designing our “2.0” analytics processing platform was that of a combine harvester – used to harvest crops and process them into neat products.
In our case the raw view data logged by the Blue Billywig player can be seen as the crops and the resulting view documents in the BB Video Analytics platform can be seen as the products.
The below flow chart provides a quick look at the components of the BB Video Analytics processing platform.
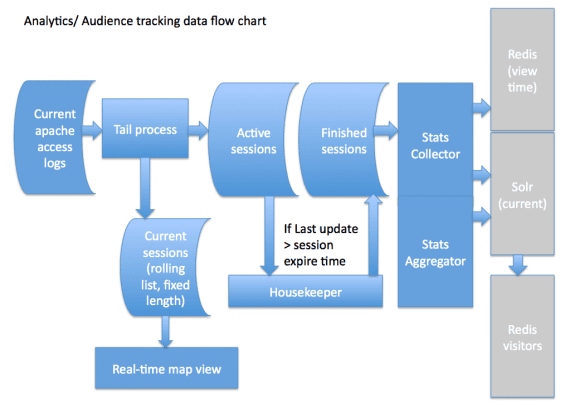
The Blue Billywig player logs events and view session information by doing requests to a web service. Those events are stored in Apache webserver formatted log files (multiple files simultaneously, each file containing a portion of the active views).
Harvester
A process called Harvester (similar to the unix “tail” command that’s probably familiar to some readers) continuously scans the log files. The Harvester gathers related events and stores them in an in-memory ultra fast database (Redis) in a list called ‘Active sessions’.
At the same time a rolling list called ‘Current Sessions’ containing a fixed number of ‘latest events’ is updated. This list is directly used to feed the ‘Audience Tracking’ feature of the Blue Billywig OVP. There is virtually no delay between these events being logged by the player and them being available in the OVP’s Audience Tracking feature.
There is one Harvester instance per log file, however by adding webserver instances to the analytics web service the number of log files and thus the number of simultaneously processing Harvester instances can be increased. If a ‘Finished’ event occurs for a view session the session’s unique identifier is immediately moved into a list called ‘Finished Sessions’ within the same Redis database.
Housekeeper
As long as the player runs it keeps sending events to the analytics web service around every 10-30 seconds. View sessions that never get to a finish – e.g. because the user clicks away to another page before the video is completely watched – are moved into ‘Finished Sessions’ by a component called Housekeeper after 90 seconds of session inactivity.
Collector
The ‘Finished Sessions’ list is actively monitored by multiple instances of the Collector component. This is the most CPU intensive step in the flow from raw data to analytics information. The collector combines the stored view session information with external sources like the OVP metadata backend, a mobile device information database and a geoip database. The main result of the collector’s hard work is a set of documents that are uploaded into an Apache Solr analytics storage cluster. Apart from that it stores some data for hourly aggregation and feeds a view time analysis Redis database.
Aggregator
Most view session data in the Blue Billywig Analytics platform is stored completely. Almost no data reducing technologies like map/reduce, data aggregation and probabilistic counting are used. a few metrics, specifically the number of player loads (initializations) and the number of unique visitors in a certain hour are gathered and stored by the Aggregator. Unique visitor count per publication per hour and per day is stored in Redis bitsets. This enables the analytics frontend to query unique visitor counts over any number of hours and still present accurate and fast results. This cool method is worth a read itself: http://blog.getspool.com/2011/11/29/fast-easy-realtime-metrics-using-red…
Future proof?
The base architecture of our Video Analytics 2.0 platform has been running for more that one and a half year now. It can be considered proven and stable. However, demand for more and faster analytics information continually grows. We will probably replace some storage solutions by even better/ more Cloud ready alternatives and we’ll continue to add features and metrics to our video analytics platform, but the architecture and information flow is expected to be scalable and usable for years to come. I hope to have given you a good overview of the Blue Billywig Analytics foundations and architecture.
If you have any questions or suggestions, don’t hesitate to contact us.